
Training Audio Classifiers in an Adversarial Setup

Purchased from Istockphoto.com. Copyright.
Adversarial training is a technique used to improve robustness in intelligent systems. We focused on audio classification tasks using six advanced neural network architectures applied over 2D spectrogram representations based on discrete wavelet or Fourier transforms, with or without appended chromagram information. Our experiments on two environmental benchmarking datasets demonstrated a positive impact in robustness, and a higher adversarial perturbation budget for the attacker to fool the system.
Using Image Classifiers for Audio Tasks
Intelligent systems based on deep neural networks are becoming the default option to classification tasks, mainly due to their large capacity, measured in millions of parameters, and their ability to synthesize abstract concepts, from the problem to be solved after presenting large amounts of data over and over until reaching convergence, to the expected output of the model.
Application domains in deploying neural networks are numerous beyond the classical case of using visual recognition, and this is possible thanks to one important property: transferability, or the capacity of reusing knowledge obtained from one domain to another, which in this specific case is audio classification.
To achieve such a bridge in treating soundtracks inherently represented in a one-dimensional space—inside a network architecture preconceived for bi-dimensional imagery—it is necessary to apply several digital signal processing steps, including filtering and Fourier transform, to pass from temporal representation to frequency-based information. One popular way to do this is spectrograms, a widely used tool for audio spectral analysis and a close emulation of the psychoacoustic human model of hearing.
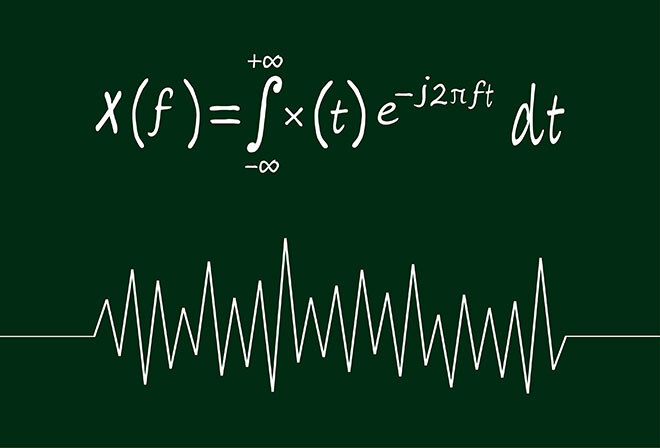
Fourier transform
Adversarial Examples as a Threat to Neural Networks
For the uninitiated, it seems that the ever-increasing computational power, sophisticated models, and availability of training data mostly available on the internet are a guarantee for artificial intelligence to succeed, but it is far from being the case. There are still many open problems, one of them being the robustness of the systems against adversarial examples—those data points close enough to the valid samples, but maliciously crafted to inject minimal perturbation and force the network to output the wrong decision.
Adversarial examples are not just random and blind spots in the input data space where a highly accurate neural network will easily fail. Instead, they are the result of the conscious exploitation of weaknesses in the system, like the cheap optimization techniques used to train networks to save resources or the lack of precision in a digital representation when encoding information in an 8-bit environment as in the case of images. But even more fundamental, many of the adversarial techniques used by an attacker are based on the very same concept of following the gradient, or variations of the signal propagating from one layer of the network to another, with the objective of finding the smallest possible perturbation to feed to a good data candidate and twist it into an adversarial example.
Training Adversarially – A Step-Up in Robustness
In our work, we explored the possibility of counteracting the negative effect of adversarial examples and making our models less prone to mistakes by adding robustness to the resulting neural network. To this end, our approach was to implement adversarially training or, simply put, intentionally incorporate crafted adversarial audio spectrograms during the training process to help the network be more resilient to them in future inference runs.
Before proceeding with the adversarial stage of our experiments, we first had to decide on the type of model to attack, and our choice was to leverage six different types of convolutional neural networks, starting from the classical AlexNet all the way up to the family of ResNet models. As for data representations, we complemented our Fourier and wavelet-based spectrograms with a harmonic change detection function (HCDF) provided by chromagram using the constant Q transform (CQT).
Once network architectures and the input features to feed them with were settled, the next step was to select proven effective attacks, most of them operating in the whitebox scenario where the attacker has complete access to the parameters of the victim’s neural network. And for the sake of sophistication, the implemented threats were targeted attacks, meaning that the adversary was able to optimize its malicious candidate to fool the network outcome to the precise wrong class expected in advance, not a random failure. In all cases, the fooling rate of all attack algorithms was set to a predefined success threshold of 90%, after fine-tuning several hyperparameters like perturbation limitations, number of iterations, and number of line searches within the manifold of samples.
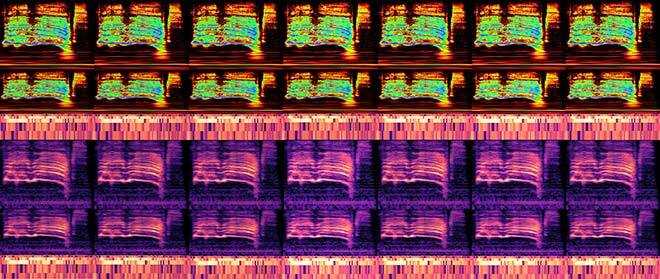
Fig. 1 Crafted adversarial spectrograms for the ResNet-56 using the six optimization-based attack algorithms at different adversarial perturbation values ϵ
The databases used to retrieve audio files were based on environmental sounds known as UltraSound8K and ESC-50, with ten and fifty different classes respectively, totalling thousands of examples. Training was performed mainly in NVIDIA’s GPUs from ETS servers.
After the models were retrained with additional adversarial examples, we witnessed a drop in performance related to the original model of the recognition accuracy. In exchange, we noticed a significant gain in robustness against the crafted adversarial examples, but in all cases adversarially training could not completely prevent the network from misclassifying the adversarial examples.
Conclusions
The main takeaway from our research is the fact that along with the robustness of the models, the cost of the necessary perturbations to be fed by the attacker to the malicious sample was considerably increased, making them impractical to use in a real-life setup without being noticed. There is still plenty of room for improvement in proposing an effective defense when facing adversarial examples, because training models with adversarial examples is a matter of trade-off between classification performance and robustness of the system, but not a remedy to eliminate potential threats.
Additional Information
For more information on this research, please read the following conference paper: Raymel, A.S.; Esmaeilpour, M.; Cardinal, P. 2020. “Adversarially Training for Audio Classifiers.” Presented at the International Conference on Pattern Recognition.

