
Multi-Criteria-Based Client Selection for Federated Learning in IoT

Purchased from Istockphoto.com. Copyright.
As an alternative to centralized models, Federated Learning (FL) was proposed to take us a step further in preserving data privacy. In FL, raw data is kept on devices, while shared models are computed locally, then aggregated globally throughout several rounds. Selecting participating clients is currently done in complete/quasi randomness. However, client heterogeneity results and their limited resources in IoT could lead to failure in completing the training task, which affects model accuracy. Therefore, we propose FedMCCS, a multi-criteria-based approach for client selection in FL. CPU, Memory, Energy, and Time are all considered for client resources and the number of clients in FedMCCS is maximized to the utmost at each round. Keywords ‒ Federated Learning, Internet of Things, Multi-Criteria Selection, Resource Management.
Challenges in Federated Learning-Based Systems
Nowadays, with the wealth of data generated by mobile and IoT devices, applications are becoming increasingly intelligent. However, the data is sent and stored in a central entity, making it a major privacy issue.
As a solution, the term Federated Learning (FL) was recently coined by Google to address data privacy. In this type of learning system, rather than sending data to the cloud, Machine Learning (ML) models are locally trained on devices. Generated models are then sent to the server for aggregation to produce an enhanced global model.
However, different sets of clients are selected in complete [1] or quasi-randomness [2] from one round to another. When the selection falls on IoT clients with limited resources, not only is a longer processing time required from the client, but also failure in completing the training task could occur, and affect model accuracy accordingly.
An Enhanced Federated Learning Protocol
To address the above-mentioned limitations, a multi-criteria-based client selection approach for FL was proposed, taking into account resource availability. Figure 1 illustrates the high-level architecture of the proposed framework. First, communication between the two entities, IoT devices and the server, is initiated to inquire about client resources. Based on the responses, a linear regression-based algorithm is performed to predict if the client has enough CPU, memory, and energy to perform the training task. Estimation time for model download, update, and upload is also calculated and compared to a threshold defined by the server.
With these metrics, the proposed approach is capable of maximizing the number of selected clients, aggregating more updates per round and minimizing total communication rounds.
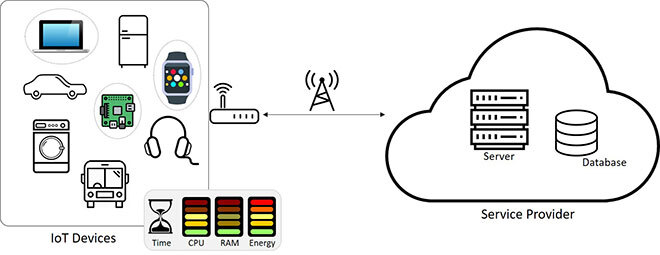
Figure 1. High-Level Architecture of the Proposed Framework.
Validating the Proposed Approach
In a case study, we considered network intrusion detection, where good models can distinguish between good/normal connections and intrusions/attacks. For this task, we used the NSL-KDD [3] dataset and considered 100 clients, where a maximum of 10 was selected for each round.
We compared our approach with the following two baselines:
- VanillaFL: The original FL approach [1] where 10 clients are randomly selected by the server to participate in the FL rounds.
- FedCS: FL with client selection [2], where 10 random clients are first selected by the server to share their resources. FedCS, representing only the time needed to obtain client updates, was used for client selection.
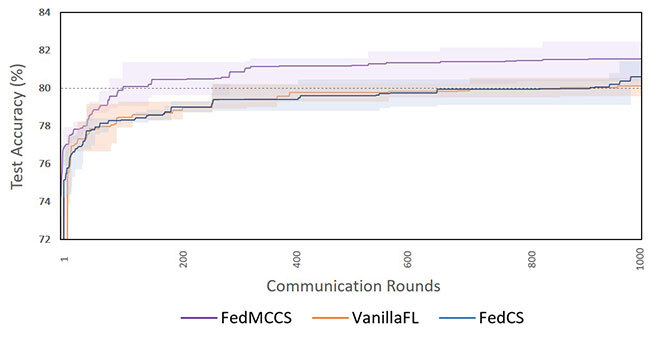
Figure 2. Test accuracy vs. communication rounds
Figure 2 shows the number of communication rounds needed to achieve 80% accuracy. The shaded areas represent the standard deviation of five performed executions. Note that our FedMCCS approach outperforms the other two in terms of communication rounds. To reach 80% accuracy, FedMCCS requires 108 rounds, while this number increases 8.0 x for the VanillaFL with 861 rounds, and 8.4 x for the FedCS with 912 rounds. We interpreted such results by the fact that we had more clients participating in the FL rounds.
The variation of selected clients able to finish training without dropping out was also studied. Particularly, Figure 3 shows that FedMCCS selects the highest number of performant clients, by considering many criteria (CPU, Memory, Energy, and Time) affecting dropouts.
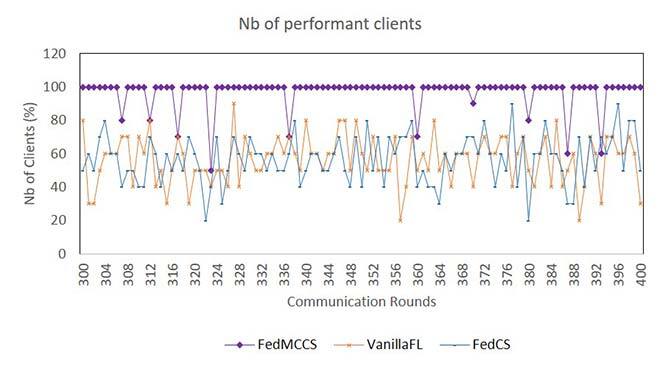
Figure 3. Variation of the number of selected clients per round
On the other hand, a round is considered discarded when less than 70% of the selected clients do not send their model parameters to the server. Our experiments show that FedMCCS yields only a few discarded rounds, compared to the other two, as shown in Figure 4. Therefore, we can see that the more clients we have, the more accuracy we get, and the smaller number of discarded rounds we obtain.
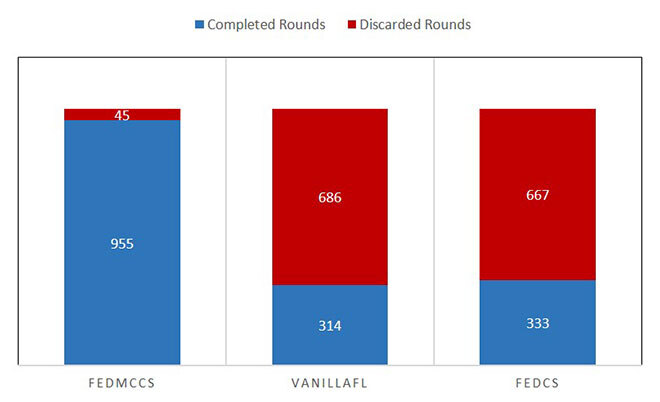
Figure 4. Completed vs. discarded rounds in 1000 FL rounds
Conclusion
Our proposed FedMCCS is an enhanced Federated Learning with multi-criteria client selection; particularly an optimization scheme, which can efficiently select and maximize the number of clients to participate in each round, while considering their heterogeneity and their limited communication and computation resources.
Real life experiments demonstrate that FedMCCS is able to train and produce high-performant ML models with few rounds of communication, compared to state-of-the-art protocols and approaches.

