
Emotion Recognition with Spatial Attention and Temporal Softmax Pooling

Purchased from Istock.com Copyright.
Video-based emotion recognition is a challenging task because it requires distinguishing between slight deformations in the human face that represent emotions, and no change in front of stronger visual differences, due to different identities. In the last few years, facial features extracted by deep neural networks have proved to be a huge leap in emotion recognition. In this work, we propose a simpler approach that combines Convolutional Neural Networks (CNN) [1] pre-trained on a public dataset of facial images with (1) a spatial attention mechanism to localize the most important regions of the face for a given emotion, and (2) a temporal pooling mechanism to select the most important frames of the given video. Keywords: Affective Computing, Emotion Recognition, Attention Mechanisms, Convolutional Neural Networks.
Emotion Recognition: A Challenge
Emotions are one of the implicit channels that humans use to communicate with each other. Having a computer system understand and respond to human emotion is necessary for a successful human-machine interaction. In the last few years, with the advancement of technology, interpretation of the explicit channels has become increasingly feasible. For instance, speech processing systems can easily convert a voice to text, or computer vision systems can detect a face in an image. Recently, emotion recognition has attracted attention from not only the computer vision community, but also the natural language and speech processing community, because state-of-the-art methods are finally providing results that are comparable to human performance.
Designing a system capable of encoding discriminant features for video-based emotion recognition is challenging because the appearance of faces may vary considerably according to the specific subject, capture conditions (pose, illumination, blur), and sensors. It is difficult to encode common and discriminant spatial-temporal features of emotions while suppressing these contexts and subject-specific facial variations.
To tackle wide-based emotion recognition, our pipeline was comprised of four stages: preprocessing, feature extraction, spatial pooling, and temporal pooling.
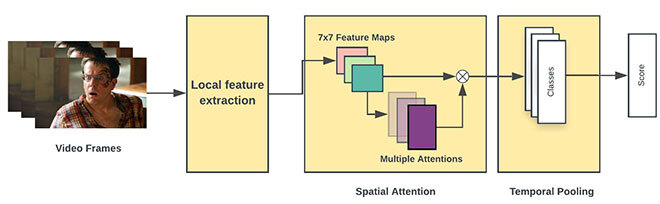
Figure 1 Overview of methodology
Preprocessing
If you think of video from a visual perspective, facial expressions generally convey most of the emotional information. However, in each frame of a video, apart from the human face, there are many unrelated objects. So, the first task is to extract the face from each video frame.
Feature Extraction
In this stage, the extracted raw faces within each frame are fed to pre-trained convolutional neural networks (CNN). Think of CNN as a model that takes in an input image and passes it through a series of learnable filters (Kernels) and assigns importance to various aspects/objects in the image. At the end of this stage, we get the facial features corresponding to an emotion within each frame in the video.
Spatial Pooling
CNN processes the image at each layer of the model by reducing the input resolution and increasing the output depth (features). Back to the emotion recognition task, more than one part of the face contributed to the facial expression, and many parts of the face simultaneously affected the outcome. Consequently, our hypothesis is that by explicitly focusing on important regions of the face the model can further benefit from the CNN features. Hence, we used the attention network in this stage. Attention models [2] increase the interpretability of deep neural network’s internal representations by capturing the area where the model is focusing its attention when performing a task.
Temporal Pooling
Until this stage, all the previous ones focused on an individual frame within one video. All the frames within a video contribute to the final emotion. Therefore, we need to consider facial expressions over time to better understand the emotion associated with the video. The most common approaches—using the one with higher value (Max pooling) or averaging values (Average Pooling) over the video—either totally ignore or aggressively smoothen the relationship between each frame in a video. In order to compensate those problems, we utilized a new aggregation method, which acts as something in between. We also compare our new temporal pooling approach with LSTM [4] which is a special type of neural network with the capability to take into account the temporal dimension.
Evaluation of the Proposed Approach

Figure 2 Sample from the AFEW database
We evaluated our models based on the AFEW database, which is used in the EmotiW audio-video sub-challenge [3]. AFEW is collected from movies and TV reality shows; it contains 773 video clips for training and 383 for validation with 7 various emotions: anger, disgust, fear, happiness, sadness, surprise, and neutral. Sample images from the dataset are illustrated in Figure 2. The result of spatial attention is best shown visually. In Figure 3, each ground truth frame within a sequence has a corresponding heatmap showing the attended regions of the face, and one chart demonstrating the importance of emotions associated with that particular frame. From the second heatmap, it is clear that throughout the frames, the model not only captures the mouth—which in this case is the most important part in detecting the emotion—but the last three frames focus on the eyes as well.
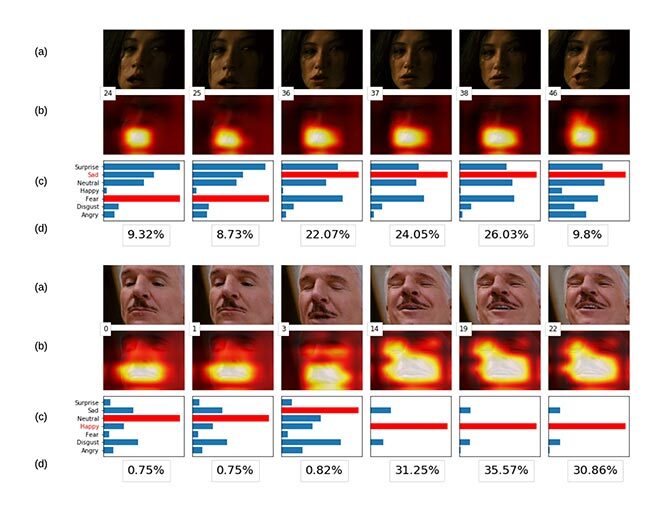
Figure 3 Video frames of time steps for an example of sadness and happiness. The percentage below the charts represent temporal importance for selected frames. To make those values more meaningful they have been re-normalized between 0 and 100%.
In Table 1, we report the performance of our model. Compared to baseline models our method achieves higher accuracy.
Table 1: We evaluated the performance of the proposed spatial attention and temporal pooling, and compared
it to a baseline model which had none.

Conclusion
In our work, we presented two simple strategies to improve the performance of emotion recognition in video sequences. First, we used an attention mechanism to spatially select the most important regions of an image. Second, we showed that by considering the relationship within each frame in a video, not only does the model select the most important frames of a video but it can also lead to promising results.
Additional Information
For more information on this research, please read the following paper, which was granted the Best paper Award: Aminbeidokhti, M.; Pedersoli, M.; Cardinal, P. Granger, E. 2019. “Emotion Recognition with Spatial Attention and Temporal Softmax Pooling”. In: Karray F., Campilho A., Yu A. (eds) Image Analysis and Recognition. ICIAR 2019. Lecture Notes in Computer Science, vol 11662. Springer, Cham.

