
Boosting Machine Learning Speed with Hardware

Bought on Istock.com. Copyrights.
Machine learning (ML) has become widespread. Among the benefits of ML is its ability to extract models from data with minimum human involvement. The process of obtaining a model requires high-density computing power far beyond the capabilities of traditional computing processors like general-purpose central processing units (CPUs). With regular processors, the ML process is time-consuming and unaffordable. To improve ML performance, we propose a new hybrid design approach based on Graphics Processing Units (GPU), Field Programming Gate Arrays (FPGA), and CPUs in implementing the ML process. This approach has been proven to offer overwhelming advantages compared with standard ML architectures. Keywords Machine Learning, GPU, FPGA, High Performance Computing, Neural Network
Enhancing Calculation Power with GPU and FGPA in Parallel
Today machine learning (ML) is booming, and a lot of ML applications are emerging, such as game AI, auto driving, diagnosis assistant, auto trading, and face recognition. These dramatically improve human life quality and work efficiency. However, there is no free lunch. Figure 1 depicts a general and straightforward deep neural network (DNN), which is the foundation of most complex neural networks (NNs). The figure also shows how to calculate a node value on a hidden layer. The resulting computation now shows matrix multiplications and matrix additions. For this node, maybe the calculation is not too complex. However, when expanding the node to the whole NN, which usually has tens of thousands, sometimes even millions or billions of nodes, we get a different story. Now, it consumes much high-density computing power and is no longer an easy task.
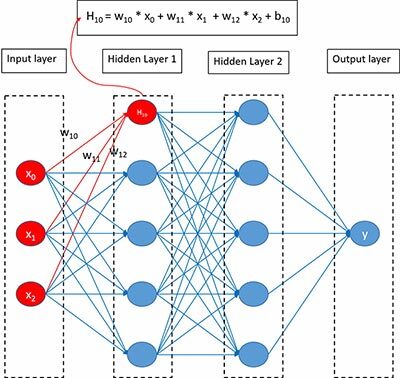
Figure 1 Example of DNN computing.
To handle such a tremendous job, we need powerful processors. According to our previous analysis, MLs are composed mainly of massive matrix operations. All of these operations can be done in parallel. Therefore, hardware devices that have sizable parallel computing units are required. Figure 2 shows the current primary hardware computing devices. Traditional processors such as CPUs, which have few computing cores and execute commands in sequence, cannot meet this high-density computing requirement. Graphics Processing Units (GPUDef. “A graphics processing unit (GPU) is a specialized electronic circuit designed to rapidly manipulate and alter memory to accelerate the creation of images in a frame buffer intended for output to a display device.” Wikipedia https://en.wikipedia.org/wiki/Graphics_processing_unit), which have many parallel computing units, are perfect for parallel computing. Field Programming Gate Arrays (FPGA) have a lot of configurable logic blocks which can be configured into any function including additions and multiplications. Notwithstanding the cost, FPGADef. “A field-programmable gate array (FPGA) is an integrated circuit designed to be configured by a customer or a designer after manufacturing – hence the term field-programmable “. Wikipedia. https://en.wikipedia.org/wiki/Field-programmable_gate_array has the most significant parallel design space. One can not only decide how to distribute computing tasks on hardware resource, but also design each configurable logic block function to reach the highest performance. If budget is limited and extreme performance is not an issue, the GPU plan can be selected. GPUs have tremendous ready-made parallel computing units, which could be programmed directly.
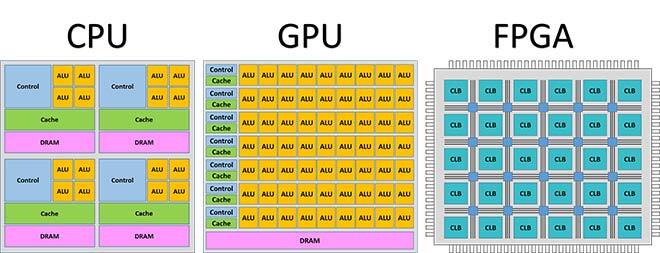
Figure 2 CPU, GPU and FPGA architectures.
Currently, much work has been done on using GPUs only to accelerate MLs (Raina, Madhavan et al. (2009), Bergstra, Bastien et al. (2011), Bergstra, Bastien et al. (2011), Potluri, Fasih et al. (2011)), or on using only FPGAs to accelerate the inferencing phase of an ML process (Motamedi, Gysel et al. (2016), Qiu, Wang et al. (2016), Nagarajan, Holland et al. (2011), Nagarajan, Holland et al. (2011)). However, according to our research works (Liu, Ounifi et al. (2018), Liu, Ounifi et al. (2019)) it is best to combine GPUs and FPGAs to implement MLs in order to obtain the highest performance.
Proposed Hybrid Architecture
A standard ML system has two phases: a training phase and an inferencing phase. The training phase is in charge of training the model from datasets, and the inferencing phase—also called prediction—uses the model obtained from the training phase and new input data to conduct predictions. For example, take tens of thousands of handwritten digit images in which each image has a label precisely identifying the digit of the image: first, we use these images and labels to train a model to predict the exact digit on a handwritten digit image. We call this process model training. And once we obtain the model, we can use it to predict a new handwritten digit image and get the digit of the new image. This is called prediction or inferencing. In a nutshell, training is applying a formula, inference is inputting a number into a formula to obtain a result.
As the training phase needs to build the model from massive data, it consumes much more computing power. Moreover, training parameters are often adjusted. GPU programming is more flexible than FPGA programming, and once a satisfied model is achieved, the training module’s mission is over. Elastic and high-density computing capability is crucial in the training phase, which is why we decided to use a GPU to implement the training phase.
In contrast, the inferencing phase is much simpler. A training phase contains many cycles of forward propagation and backward propagation calculations. An inferencing phase is a one-time only forward propagation calculation. Also, on a relatively long period, we will make predictions with the model time and time again. Any small latency or power consumption increase for each cycle can add up to a considerable amount. Therefore, low latency and power consumption are more desirable than flexible and high-density computing capabilities during the inferencing phase. Consequently, we selected an FPGA to execute the inferencing module.
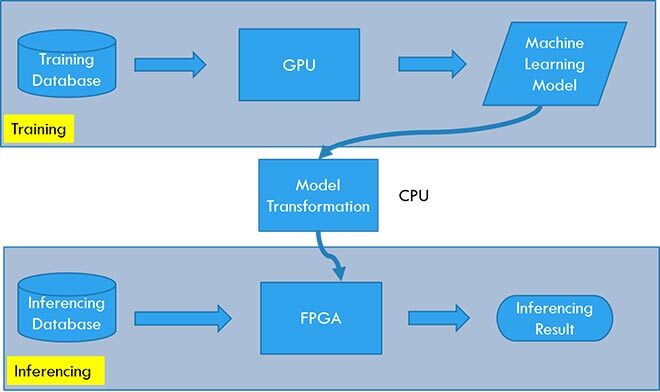
Figure 3 System architecture.
Figure 3 presents the entire architecture of our ML system, which contains two main modules, i.e. the training module carried out by the GPU and the inferencing module carried out by FPGA.
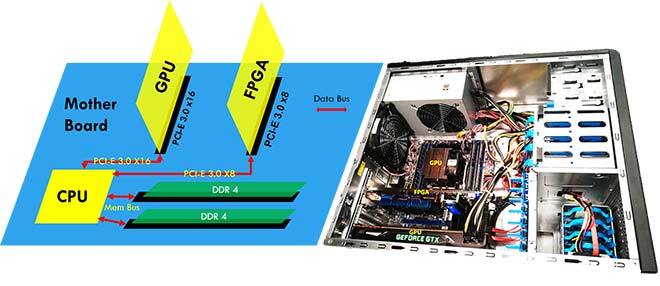
Figure 4 Schematic and real photo.
Figure 4 is the diagram representation and real picture of our proposed ML implementation.
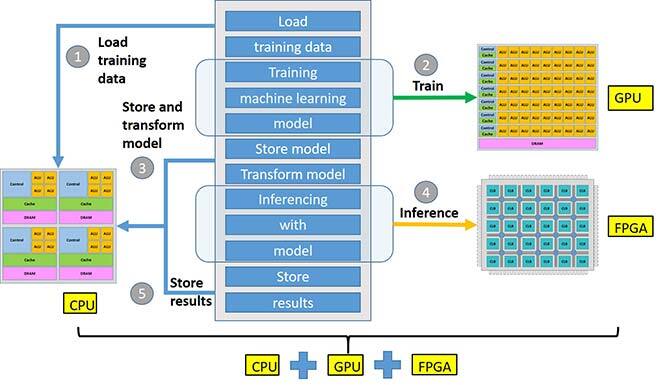
Figure 5 Hybrid machine learning flow.
Figure 5 shows the workflow of our hybrid machine learning system. First, the CPU loads the training data from storage and then sends the data to the GPU, giving the signal to GPU to start the training. After GPU training, the CPU retrieves the model from GPU, stores the model into storage, and transform the model to match the inferencing framework. Then the CPU sends the model, data, and signals to the FPGA to start inferencing. After the inferencing phase, the CPU retrieves back the results and saves or uses them for future tasks.
Training and Inferencing Speed
To verify our methodology, we conducted two experiments: training and inferencing. During both experiments, we used a database of handwritten digits as our training and testing dataset, which is a training set of 60,000 examples and a test set of 10,000 examples. The CPU model is Intel(R) Xeon(R) CPU E5-1620 v4 @ 3.50GHz. The GPU model is NVIDIA TITAN Xp, and the FPGA model is Intel Arria 10 GX.
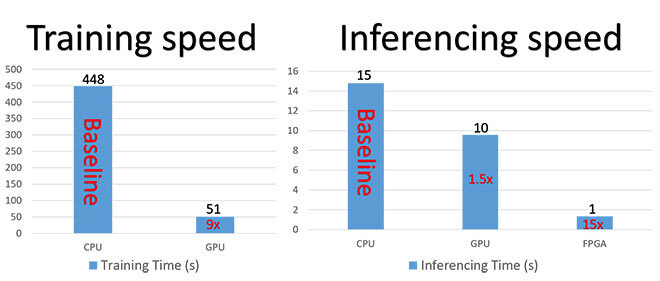
Figure 6 Training speed and inferencing speed.
Figure 6 shows the results of the experiments. When conducting the same training task on CPU and GPU respectively, we obtained similar accuracy but different speeds. The GPU training speed was about 9 times faster than the CPU. Meanwhile, when we conducted the same inferencing task on the CPU, GPU, and FPGA, the accuracy was similar, but the speeds were critically different. The FPGA speed was about 15 times faster than the CPU, and the GPU speed was about 1.5 times faster than the CPU.
These results show the tremendous potential of our hybrid ML design approach. They also demonstrate its high-performance capabilities in implementing the ML training part on the GPU and the inferencing part on the FPGA.
Conclusion
We first analyzed the standard machine learning process and the three primary hardware computing device architectures, and discussed why high-density computing power is causing a bottleneck for ML. To address this problem, we proposed a hybrid ML design methodology where we use the GPU to do the training job, and the FPGA to inference the results. Moreover, we have provided some quick explanations as to why this is the best combination. Finally, we conducted two experiments to verify our hypothesis.
Additional Information
For more information on this research, please refer to the following conference article: Liu, Xu; Ounifi, Hibat-Allaha; Gherbi, Abdelouahed; Lemieux, Yves; Li, Wubin; Cheriet, Mohamed. 2019. “A Hybrid GPU-FPGA based Design Methodology for Enhancing Machine Learning Applications Performance”. Journal of Ambient Intelligence and Humanized Computing: 1-15.

