
Autoscaling of IoT Services for Efficient Edge Resource Utilization

Purchased from Istock.com. Copyright.
The edge-computing concept allows to convey the workload of IoT systems from the Cloud to edge nodes. It has been widely embraced by industrial applications and academic research. However, IoT devices at the edge network are generally resource-limited and heterogeneous. This limits service deployment ability on IoT edge devices. The current container-based solutions lack elasticity in terms of auto-scaling of services in relation to the resource utilization of edge devices and service performance state. We propose an approach to overcome these limitations through an auto-scaling process based on a MAPE-K loop and our proposed rule and deployment models. Our evaluation shows the efficiency of the proposed approach in adapting the system performance to meet service performance requirements and the availability of system resources. Keywords: Edge Computing, Container, Resource Management, Auto-Scalability.
Deployment Challenges on IoT Edge Devices
The Internet of Things (IoT) applications have become ubiquitous and their influence in several areas of our daily lives is indispensable. These applications are mostly reliant on networks composed of tiny devices dipped into our surroundings, for instance, in the form of environmental, healthcare, and industrial sensors. These devices are in an ongoing process of development and deployment, leading to billions of devices connected to the Internet (Evans 2011).
Edge devices have imparted significant benefits to IoT networks by assuming some cloud tasks, alleviating the workload imposed on the network and improving system responsiveness. Nevertheless, IoT devices at the edge network are likely to be resource-limited, and they perform under an extremely heterogeneous environment in terms of connected devices and deployed software modules. Thus, both aforementioned concerns have considerably hindered the deployment process of services on IoT edge devices. Lightweight virtualization technologies, such as containers, have been widely adopted to facilitate service deployment and management on IoT edge devices (Ahmed et al. 2019). Containers provide the advantage of packaging and running IoT services and their dependencies in isolated and self-contained modules. Moreover, container orchestration techniques, such as Swarm, enable resource sharing between IoT edge devices within the same cluster and provide a means of communication between containers across virtual networks.
However, these tools lack elasticity in terms of up/down auto-scaling of service instances in relation to the resource utilization of all cluster elements, as well as service performance metrics.
Proposed Auto-Scaling Approach
We insist on the utmost necessity of investigating solutions to optimize container-based IoT service deployment on network edge devices—taking into consideration their resource restrictions—and to automate a fair distribution process of these services on devices within the same edge cluster.
Reference Knowledge
The auto-scaling process is based on a shared knowledge represented by our proposed rule and deployment models.
In the rule model (Figure 1 presents a simplified version), we defined four categories of rules, namely evaluation, decision, scale, and verification. Each one corresponds to a specific step of the proposed auto-scaling process. Figure 2 presents the system components involved in the deployment process. Accordingly, an instance of this model is created at each deployment.
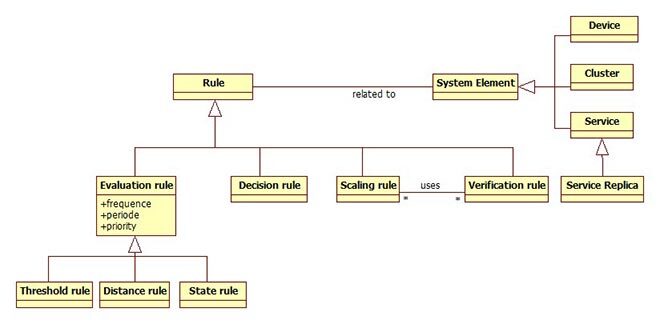
Figure 1 Simplified Rule Model
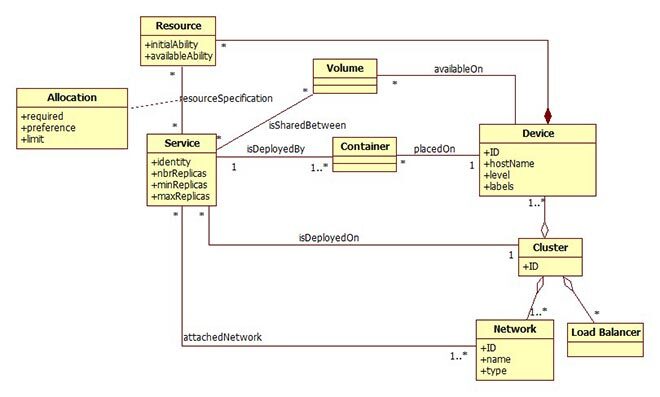
Figure 2 Part of the deployment model
Auto-Scaling Process
The auto-scaling process is inspired by MAPE-K (Monitor-Analyze-Plan-Execute over a shared Knowledge) loop (Computing 2006). As presented in Figure 3, the process is composed of five steps, namely:
- Monitoring: periodical collecting of the different system metrics;
- Evaluating: determining the current state of different system elements and, therefore, its overall state;
- Decision making: analyzing the result of the evaluation step in order to make a decision about the need for scalability (whether up or down) of each system element;
- Generating a scaling plan: generating the overall scalability plan based on the elementary decisions of the system elements obtained in the previous step; and
- Executing the scaling plan: executing the scalability operations recorded in the generated plan.
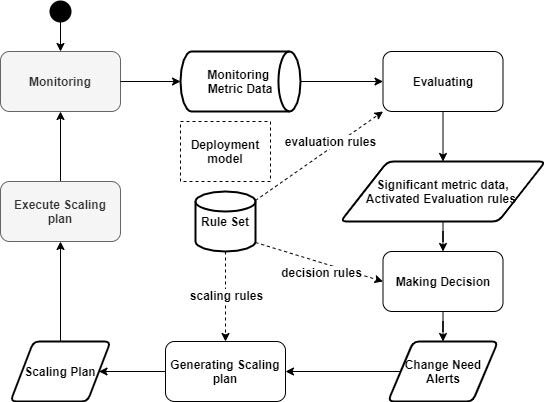
Figure 3 Proposed Autoscaling Process
Note that we have proposed different algorithms and strategies to carry out the different steps of this process.
Evaluation of the Approach
The implementation and deployment of our approach is based on a set of monitoring and management tools that are widely used by the DevOps and Container community, namely NodeExporter, cAdvisor, Prometheus, Grafana, Jenkins, and AlertManager.
In evaluating the proposed approach, several criteria are considered, such as CPU, memory utilization, and network traffic, as well as response time as a service performance metric.
As shown in Figure 4, the service scales down the number of replicas because the response time is over expectation. In Figure 5, however, the service scales up (increases the number of replicas) as long as the response time is under expectation.
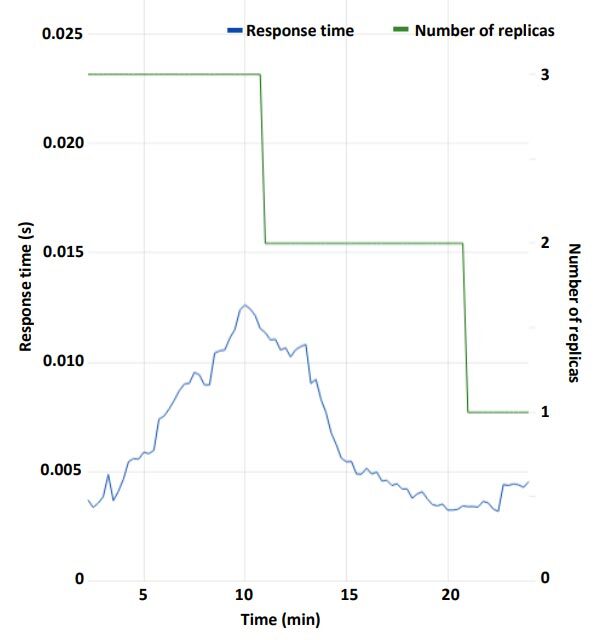
Figure 4 Scalability in the over-expectation case
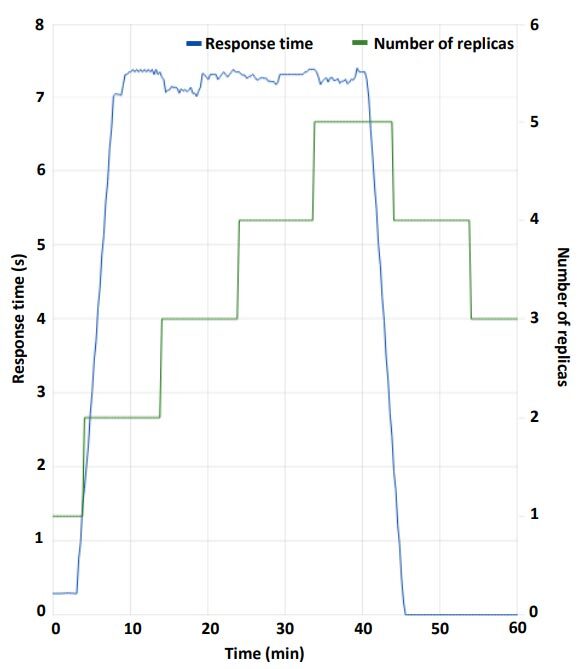
Figure 5 Scalability in the under-expectation case
Therefore, the use of resources adapts to the service state. Taking the CPU usage as an example, Figure 6 shows that resource utilization is directly proportional to the number of replicas.
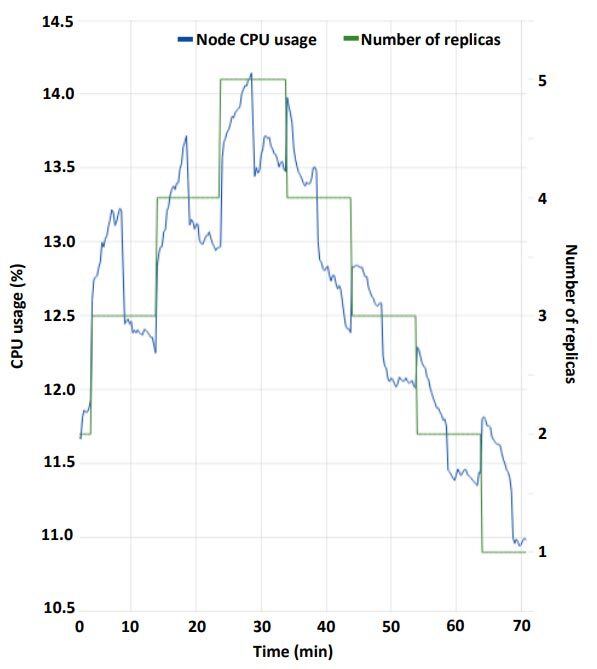
Figure 6 CPU usage during the scalability
Conclusion
To obtain an efficient auto-scaling of service deployment on IoT edge devices, this research presents a solution based on proposed knowledge models and an auto-scaling process, as well as lightweight virtualization technologies, namely containers. Results proved the efficiency of our approach in terms of auto-scaling of services in relation to service performance metrics (e.g. response time), while optimizing resource utilization, such as CPU, memory, and network traffic.
Additional Information
For more information on this research, please refer to the following paper:
Bali Ahmed; Al-Osta, Mahmud; Ben Dahsen, Soufiene; Gherbi Abdelouahed. Rule based auto-scalability of IoT services for efficient edge device resource utilization. Journal of Ambient Intelligence and Humanized Computing (2020).

