
Propagation de l’information dans les réseaux neuronaux profonds
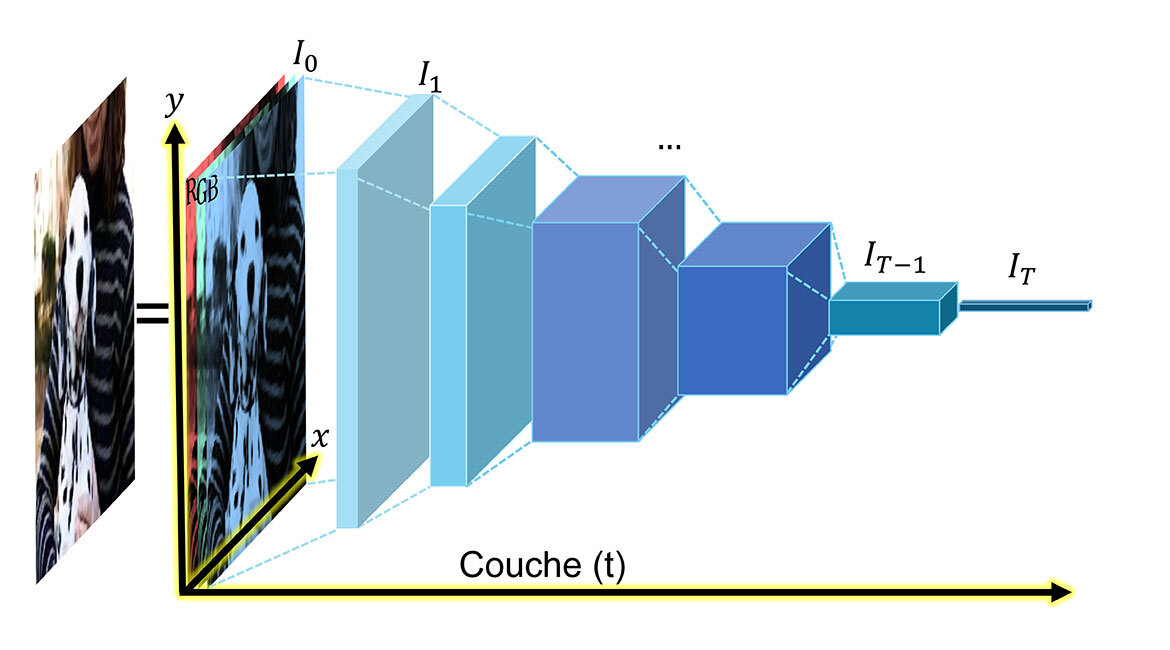
Image RVB et d’un réseau profond de base (réseau neuronal évolutif CNN, style VGG démontrant notre représentation (t, x, y) de l’information propagée dans le réseau. @ aux auteurs.
Nous modélisons et cherchons à comprendre comment les machines « perçoivent » l’information dans les réseaux neuronaux profonds (deep neural networks, DNN) et proposons une nouvelle approche d’entraînement optimisé pour contrer les biais algorithmiques intrinsèques. Plus précisément, nous avons pu observer que les DNN semblent différencier automatiquement l’information symétrique et antisymétrique, ce qui permet de diviser la fonction d’apprentissage (fonction de coût, utilisée pour mesurer la performance du modèle et le guider dans son entraînement) en ces deux composantes. Nous proposons d’ajouter une composante antisymétrique U(1), comparable à une valeur de teinte dans le cercle chromatique, à la composante classique (symétrique) servant à l’entraînement de ces réseaux profonds.
Les images RVB comme analogie des réseaux neuronaux profonds
Les systèmes modernes de vision par ordinateur font principalement l’acquisition d’images et le traitement de l’information. On sait peu de choses sur la géométrie de l’information propagée dans les DNN, systèmes de pointe pour les tâches de classification et de segmentation (Krizhevsky, Sutskever & Hinton, 2012). Nous avons étudié la géométrie de l’information propagée dans les DNN à l’aide d’analogies simples, d’observations généralisables et d’expériences visant à présenter une nouvelle façon d’interpréter les DNN et leurs cartes de caractéristiques, ou comment les réseaux profonds représentent l’information.
D’abord, nous soulignons la simplification originale proposée, qui consiste à considérer les cartes de caractéristiques comme des images couleur (RVB). Une image RVB, comme le montre la figure en en-tête, est une représentation visuelle comportant trois canaux : rouge, vert, bleu. Ces canaux sont la réponse de l’image aux filtres de chaque couleur qui nous renseigne sur l’intensité spectrale. Chaque pixel de l’image se décline en cinq dimensions : position spatiale 2D (x, y)+ et 3D (R,V,B) représentant les réponses des filtres de couleurs primaires sur une gamme de fréquences électromagnétiques de (400-750 THz), et des longueurs d’onde (rouge, vert, bleu) de (620-750 nm, 495-570 nm, 450-495 nm), soit presque une octave ou une fréquence doublée.
Ainsi, une image RVB individuelle est une carte de caractéristiques DNN tridimensionnelle (couches de réseau profond multicanaux identiques, dérivées des réponses des filtres de convolution) habituellement implantée dans les processeurs graphiques (GPU). La perception humaine des couleurs repose en grande partie sur la nuance, pouvant être représentée par un angle θ du cercle chromatique dans l’espace RVB (Fig 1). De manière similaire, nous proposons des couches DNN arbitraires, en modélisant l’information d’intensité multicanal en angles θ dans l’espace des caractéristiques DNN analogues à la nuance de couleur. De cette façon, la « couleur » peut être attribuée aux pixels du réseau neuronal, par exemple dans un réseau neuronal convolutif (CNN) entraîné avec des images, où les pixels de couches multiples t sont associés à un ensemble de réponses du filtre multicanal I(x,y) à des points (x,y) dans une image, comme les images RVB. Ce modèle relie les informations d’activation des réseaux de neurones profonds à la perception humaine des couleurs et servira à comprendre le flux d’informations dans les DNN d’un point de vue intuitif, en plus d’augmenter les performances.
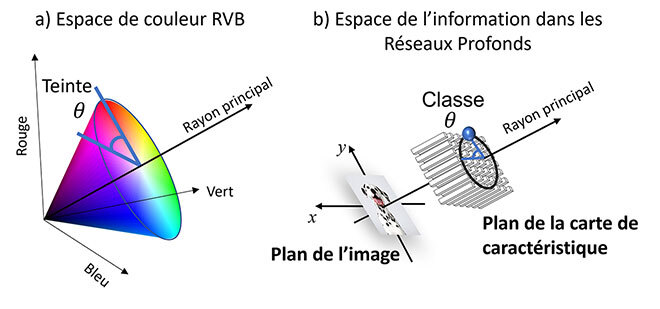
Figure 1 – Illustration des systèmes de coordonnées polaires. a) Espace couleur rouge-vert-bleu (RVB) à 3 canaux avec angle de teinte θ. b) Sous-espace à 3 canaux de la sortie ImageNet, Deng et al. (2009), à 1000 canaux, après le goulot d’étranglement spatial, montrant un angle de classe θ analogue à la nuance de la couleur et défini par la classe de l’image d’entrée. Espace où une image de dalmatien est envoyée dans un réseau CNN préentraîné sur ImageNet convergeant vers un angle précis.
Ajout à l’approche 1 parmi n (one-hot vector)
Nous estimons que la géométrie de l’image, par exemple la position spatiale (x,y), peut être aussi importante que l’information d’activation du DNN (I), comme c’est le cas dans les images RVB. La position du pixel est importante pour détecter les relations entre les objets. Pourtant, la plupart des approches ne tiennent pas compte des informations spatiales dans les couches profondes des DNN, pour ce qui est des cartes de caractéristiques, et s’appuient sur des méthodes qui ne s’intéressent qu’aux valeurs moyennes de ces cartes de caractéristiques. Souvent, la fusion de toutes les informations spatiales en une seule représentation globale cause la perte de renseignements utiles. L’approche habituelle d’entraînement de réseaux profonds est d’appliquer cette représentation globale pour évaluer les performances du modèle dans sa tâche. Par exemple, une tâche de classification prendrait les cartes de caractéristiques finales, devenue un vecteur de caractéristiques d’un seul pixel ou vecteur « one-hot », et le comparerait avec les résultats prévus pour guider le modèle pendant l’entraînement.
Ce vecteur « one-hot » a démontré son potentiel à de nombreuses reprises. Néanmoins, nous pensons qu’il n’est pas optimisé pour les DNN en raison de cette perte d’informations spatiales (positions x, y). Ainsi, nous conservons cette composante et y ajoutons une seconde composante représentant une position spatiale sous la forme d’une seule valeur, l’angle θ. Cet angle se rapporte à une nuance dans un cercle chromatique tridimensionnel, où nous maximisons déjà le contraste et la saturation (dans notre cas à l’aide de notre premier composant « one-hot ») et où nous voulons préciser davantage la couleur à l’aide d’une valeur angulaire, comme le montre la figure 1. Cette étiquette complémentaire, que nous appelons U(1), sert à l’apprentissage du DNN (Réseaux de neurones convolutifs (CNN) dans notre cas) et apporte une petite mais constante amélioration de la précision pour toutes les tâches testées, comme le montre le tableau 1. Dans ce cas, une bonne classification apparaît près de l’angle de la classe attribuée, comme un pixel brillant et de haute intensité maximisant la saturation et la luminosité à une couleur donnée. Une classification incertaine (faible confiance dans le modèle) n’aurait aucun angle prédit en particulier, comme un pixel grisâtre.
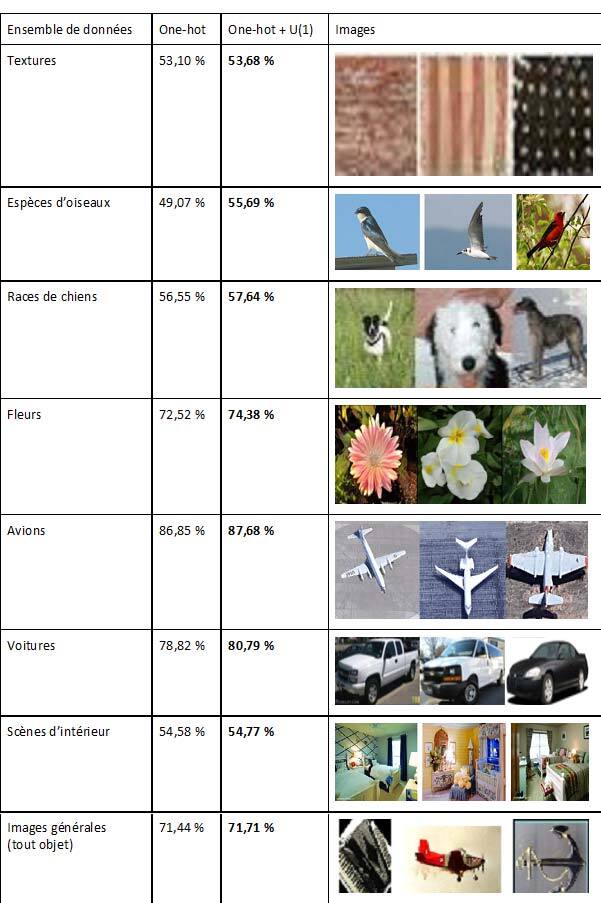
Tableau 1 – Degrés de précision (/100) de diverses tâches de classification où l’objectif est d’identifier ce qui apparaît dans les images. Les résultats démontrent le pourcentage d’images correctement identifiées après entraînement sur l’ensemble de données avec l’approche « régulière » 1 parmi n et l’approche 1 parmi n avec notre composante ajoutée.
Ces améliorations, petites, mais constantes, montrent la pertinence d’ajouter une composante spatiale à la fonction (fonction de perte) pour l’entraînement des réseaux profonds, qui, selon nous, peut être beaucoup plus révélatrice si elle est optimisée correctement. Nous avons confirmé cette tendance pour une multitude d’architectures de réseaux profonds et de nombreuses tâches et de complexités variables. Ce travail sert de preuve de concept de notre théorie U(1), mais propose surtout une nouvelle approche d’entraînement optimisée face aux biais algorithmiques intrinsèques que nous avons observés. Voir notre publication Bouchard et al. pour plus de détails (2022).


