
Parvenir à segmenter des formes à partir d’un seul exemple

Anolytics.ai. Aucune restriction d’usage connue.
Lorsqu’un enfant voit une voiture pour la première fois, il acquiert instantanément la capacité de reconnaître de nouveaux modèles de voitures, même différents. En fait, l’être humain possède l’impressionnante capacité de s’adapter rapidement à de nouvelles tâches, comme reconnaître de nouveaux types d’objets ou les sons d’une nouvelle langue, à partir d’une supervision passée très limitée. Par comparaison, les réseaux profonds modernes entraînés à classer des voitures et des camions auraient typiquement besoin de centaines d’images annotées de vélos pour acquérir la capacité de les reconnaître de manière fiable, aussi simple que cette nouvelle tâche puisse paraître. Dans cette étude, nous avons entrepris de segmenter des objets dans des images, activité courante dans des applications industrielles clés comme l’imagerie médicale ou la conduite autonome, là où l’annotation des données peut s’avérer trop coûteuse. Nous proposons une méthode simple qui permet à un modèle d’utiliser ses connaissances passées pour apprendre à segmenter de nouveaux types d’objets à partir d’un seul exemple annoté.
Les données, un frein à la segmentation
Pour flouter l’arrière-plan, les algorithmes de Zoom doivent d’abord détecter et segmenter correctement notre visage dans toute l’image. Mais comment automatiser ce processus fastidieux? C’est là une question difficile sur laquelle les spécialistes en vision par ordinateur se penchent depuis plusieurs décennies, pour des applications clés allant de l’imagerie médicale à la conduite autonome. Les modèles actuels d’intelligence artificielle (IA) qui se basent sur les réseaux neuronaux se sont révélés particulièrement efficaces dans la segmentation. Toutefois, il n’y a pas de solution miracle : ils nécessitent une quantité beaucoup plus élevée de données (épurées et annotées) pour être entraînés. Que faire alors? Dans certaines applications, un annotateur humain peut mettre plusieurs heures à annoter adéquatement tous les objets d’une seule image. Si les grandes entreprises technologiques peuvent se permettre un tel travail, la plupart des industries non spécialisées ne le peuvent pas ou ne disposent pas de l’expertise nécessaire pour former des modèles à partir de zéro. C’est là que l’apprentissage basé sur de très petits ensembles de données (technique few-shot) entre en fonction.

Figure 1 : Notre méthode en action. Le modèle n’a jamais vu de vélo. Nous lui avons fourni un seul exemple de vélo (image de gauche) et demandé de segmenter le vélo dans une autre image (deuxième image à partir de la gauche). Notre méthode de référence a donné de bons résultats, mais notre méthode raffinée a été capable de faire une capture presque parfaite du vélo.
Apprentissage avec peu d’exemples (few-shot)
Comme mentionné ci-haut, au fur et à mesure que les modèles grossissent et que les besoins en calcul augmentent, de moins en moins d’intervenants peuvent se permettre de créer de très grands ensembles de données et de diffuser publiquement les modèles formés. Les utilisateurs en aval (chercheurs universitaires ou partenaires industriels) n’ont qu’à « spécialiser » les modèles pour les tâches qui les intéressent. L’apprentissage few-shot, l’un des thèmes les plus en vogue dans le domaine de l’IA, vise à utiliser les connaissances accumulées par un modèle afin d’augmenter sa vitesse d’adaptation à des tâches nouvelles ou inédites. Ce transfert de connaissances devient de plus en plus difficile au fur et à mesure que les données « sources », soit les données à partir desquelles le modèle a été formé à l’origine, deviennent de plus en plus différentes des données « cibles », données nouvelles ou éparses auxquelles nous voulons adapter le modèle. Ce principe vaut également pour l’être humain : il est plus facile pour un francophone d’apprendre l’espagnol que l’allemand, car le nombre de racines et structures partagées est beaucoup plus élevé. L’évaluation qu’on fait actuellement des méthodes few-shot omet ce type de question et tend vers des méthodes de plus en plus complexes.
Une idée toute simple
Contrairement à la tendance actuelle, nous visons la simplicité. Au lieu de concevoir une architecture neuronale précise pour résoudre le problème, comme le font pratiquement toutes les méthodes concurrentes, nous entraînons un modèle standard au moyen d’une supervision standard. L’idée est de considérer ce modèle entraîné comme un extracteur de caractéristiques plutôt que comme un modèle de segmentation. À partir des caractéristiques produites par le modèle, nous pouvons construire un simple classificateur binaire (0 = arrière-plan, 1 = avant-plan) qui agit sur chaque pixel. Cette méthode de référence archi-simplifiée fournit déjà de bons résultats (troisième image à partir de la gauche, sur la Fig. 1). Au moyen d’outils provenant de la théorie de l’information, nous affinons considérablement la référence pour obtenir notre méthode finale (image de droite, sur la Fig. 1). Outre sa simplicité conceptuelle, le grand avantage de notre méthode est sa facilité à se coupler avec n’importe quel modèle entraîné. De plus, nous avons pu démontrer qu’elle offre des performances nettement supérieures aux méthodes existantes (tableau 1) et peut s’adapter à des changements encore plus importants de distribution des données.
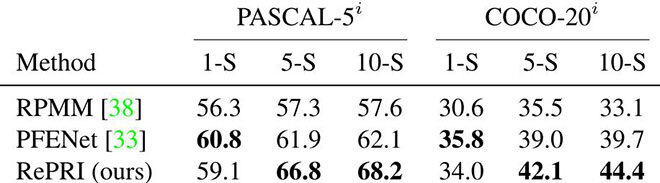
Tableau 1 : Notre méthode (dernière ligne) comparée aux méthodes concurrentielles, sur 6 scénarios. La méthode utilisée est l’intersection moyenne sur l’union (plus elle est élevée, mieux c’est). Dans 4 scénarios sur 6, notre méthode est nettement plus performante.
Conclusion
L’apprentissage few-shot tente d’atténuer le problème croissant des coûts d’annotation en spécialisant un modèle pré-entraîné à une nouvelle tâche à partir d’un seul échantillon annoté. Dans cette étude, nous avons revu les idées courantes de théorie de l’information pour créer une méthode simple et pratique de segmentation few-shot. Nous espérons que les travaux futurs continueront dans la lignée de la simplicité et porteront sur l’élaboration de méthodes adaptées aux applications du monde réel.
Complément d’information
Référence de l’article complet :
[1] Boudiaf, Malik, et al. « Few-Shot Segmentation Without Meta-Learning: A Good Transductive Inference Is All You Need? » Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
Quelques mots sur la conférence : La Conférence annuelle sur la vision par ordinateur et la reconnaissance des formes (CVPR) est considérée comme l’une des conférences les plus importantes dans le domaine et se classe parmi les 5 conférences les plus influentes, tous domaines confondus, selon les statistiques Google Scholar https://scholar.google.com/citations?view_op=metrics_intro&hl=fr.

