
Explorer le dédale de l’apprentissage par renforcement

Achetée sur Istockphoto.com. Droits d’auteur.
La dernière décennie a été témoin d’une utilisation croissante de l’apprentissage par renforcement (AR) en raison des succès obtenus. En effet, ces applications ont remporté des victoires contre des opérateurs humains dans des problèmes complexes qui requièrent un haut degré d’intelligence, comme les échecs, le go ou les jeux Atari. Cependant, les débutants dans l’apprentissage de cet outil puissant se sont généralement retrouvés dans un dédale d’algorithmes, de termes et de jargons techniques. Cet état de fait vient, en outre, compliquer la création d’une feuille de route pour guider les efforts d’apprentissage. Ici, notre objectif est de présenter une taxonomie claire des algorithmes d’AR les plus connus, qui saura guider les débutants tout au long de leur parcours vers l’étude et la maîtrise de l’apprentissage par renforcement. À la fin de cet article, nous recommandons quelques outils puissants nécessaires à la création d’applications en AR et des lectures utiles.
Qu’est-ce que l’apprentissage par renforcement?
L’apprentissage par renforcement (AR) est une branche de l’apprentissage machine (AM) qui passe par l’approche essai-erreur. Selon Rich Sutton, « les problèmes d’apprentissage par renforcement nécessitent d’apprendre ce qu’il faut faire (traduire des situations en actions) de manière à maximiser un signal numérique de récompense ». Par conséquent, l’AR a été appliqué à de nombreux problèmes qui nécessitaient une interaction avec des environnements externes : robotique, commande, communications sans fil, jeux ou négociations algorithmiques.
Le potentiel de l’apprentissage par renforcement
L’AR a démontré un grand potentiel dans la résolution de problèmes complexes, et ce, dans plusieurs domaines. Récemment, ce potentiel a été largement stimulé par la puissance accrue des techniques d’apprentissage profond. Le jumelage de ces deux techniques a donné naissance à l’apprentissage par renforcement profond (ARP) et a mené à de nombreux succès révolutionnaires. Par exemple, dans un jeu classique Atari, un agent ARP a appris à jouer à des niveaux de performance surhumains. Le système hybride ARP AlphaGo a su, quant à lui, vaincre le champion du monde du Go, un jeu très complexe. Une autre percée de l’AR au début des années 1990 a été le TD-Gammon, une technique basée sur un réseau neuronal, où des performances de niveau expert dans le jeu de backgammon ont été obtenues. Ces exemples ne sont qu’un aperçu d’un grand nombre de réalisations.
Taxonomie des algorithmes d’AR
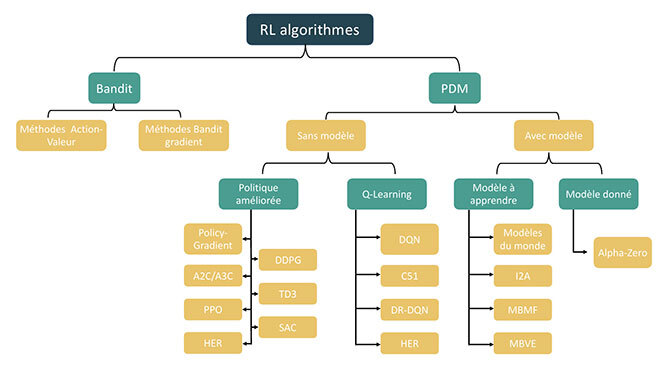
FIGURE 1. Taxonomie intuitive des algorithmes d’AR. Cette taxonomie est essentielle pour se familiariser avec l’AR. Elle sert de guide dans l’exploration des algorithmes interconnectés et superposés.
L’un des principaux défis pour toute personne souhaitant apprendre l’AR est qu’il n’existe pas de feuille de route claire des techniques et algorithmes s’y rattachant. En commençant à lire en AR, le débutant peut être confronté à une multitude d’algorithmes, ce qui rend difficile d’avoir une vue d’ensemble sur l’interconnectivité des composants. À la figure 1, nous présentons une taxonomie de haut niveau des algorithmes d’AR courants dans la littérature. Nous voyons qu’un problème donné peut tomber dans la catégorie du problème du bandit ou du processus de décision markovien (PDM) dépendant si les actions de l’agent interagissent avec l’environnement ou le modifient. Il convient de mentionner que les problèmes de PDM sont plus courants que les problèmes du bandit dans les applications réelles. Par conséquent, on constate que les algorithmes d’AR les plus célèbres relèvent des problèmes de PDM. Une taxonomie exhaustive des algorithmes d’AR partage les algorithmes en deux classes principales, selon la connaissance de la dynamique de l’environnement (le modèle) : les algorithmes avec modèle et les algorithmes sans modèle. Dans les algorithmes avec modèle, comme le nom l’indique, le modèle est censé être connu. En revanche, les algorithmes sans modèle ne nécessitent pas de connaissance préalable du modèle de l’environnement, et les interactions avec l’environnement sont explorées au moyen de l’approche essai-erreur. Une autre classification pertinente, basée sur l’objet de l’optimisation, comporte deux catégories principales : optimisation des valeurs et optimisations des politiques. Dans le premier cas, l’agent tente d’apprendre la fonction représentant la qualité de l’état ou de l’action (Q-values) et obtient ensuite la politique optimale à partir des valeurs Q. Dans les algorithmes basés sur la politique, l’agent essaie d’apprendre la politique directement au moyen d’une fonction paramétrée (ex. réseaux neuronaux artificiels). L’acteur-critique est une troisième catégorie qui combine des algorithmes d’optimisation de valeurs et de politiques. Comme le montre la figure 1, nous suivons la taxonomie qui partage les problèmes des PDM en fonction de la disponibilité du modèle de l’environnement.
Outils essentiels en AR
Pour se familiariser avec l’AR, il faut plonger et utiliser certains outils essentiels. En raison de leur popularité dans ce contexte, les outils mentionnés ici servent principalement à développer des applications d’AR en Python. D’abord, il faut un environnement de développement intégré (EDI) facile à utiliser pour commencer à développer l’application d’AR. Anaconda est l’un des meilleurs choix pour cette tâche. Il regroupe les paquets Python les plus couramment utilisés en un seul endroit. OpenAI gym est un outil de développement d’AR qui encapsule de nombreux environnements servant à développer et à valider des algorithmes AR. Pour compléter, nous nous devons de mentionner d’autres paquets d’AM utiles comme NumPy, SciPy, SK-learn et Keras-AR. La figure 2 résume certains de ces outils importants.
Conclusion
La complexité des interconnexions entre les différents algorithmes d’AR constitue un obstacle majeur pour les débutants. Dans cet article, nous fournissons une vue d’ensemble des algorithmes d’AR afin d’aider le lecteur dans un apprentissage autoguidé.


