
Des classificateurs audio plus résistants aux attaques adverses

Achetée sur Istockphoto.com. Droits d’auteur.
L’entraînement adverse est une technique qui sert à améliorer la robustesse des systèmes intelligents. Nous nous sommes penchés sur la classification audio effectuée par six réseaux neuronaux d’architecture avancée appliquées à des représentations de spectrogrammes 2D, basées sur des transformées en ondelettes discrètes ou de Fourier, avec ou sans information chromatographique. Nos expériences sur deux ensembles de données d’étalonnage environnemental ont démontré une amélioration de la robustesse et un budget de perturbations plus élevé pour l’adversaire qui cherche à tromper le système.
Des classificateurs d’images pour les tâches audio
Les systèmes intelligents fonctionnant à partir de réseaux neuronaux profonds sont en voie de devenir l’option par défaut des tâches de classification, principalement en raison de leur grande capacité (calculée en millions de paramètres) et de leur habileté à synthétiser des concepts abstraits, de la résolution de problème sur réception de grandes quantités de données pour atteindre la convergence, jusqu’au résultat attendu du modèle.
Les domaines d’application des réseaux neuronaux sont nombreux, bien au-delà du cas classique de reconnaissance visuelle, et rendus possibles grâce à une propriété importante : la transférabilité ou la capacité de réutiliser les connaissances obtenues d’un domaine à un autre qui, dans le cas présent, est la classification audio.
Pour pouvoir traiter des bandes sonores représentées dans un espace unidimensionnel (dans une architecture réseau conçue pour l’imagerie bidimensionnelle) il est nécessaire de procéder à plusieurs étapes de traitement numérique du signal, notamment le filtrage et la transformée de Fourier, passant ainsi de la représentation temporelle à l’information fréquentielle. La méthode répandue est le spectrogramme, outil largement utilisé pour l’analyse spectrale de l’audio émulant le modèle psychoacoustique de l’audition humaine.
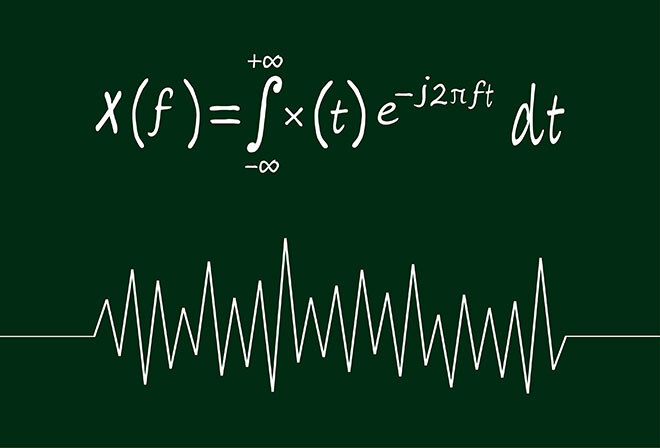
Transformée de Fourier
L’exemple adverse, vecteur de menace des réseaux neuronaux
Pour le non-initié, la puissance informatique sans cesse croissante, les modèles de plus en plus sophistiqués et les données d’entraînement offerts pour la plupart sur Internet offrent une garantie de succès en intelligence artificielle, mais c’est loin d’être le cas. Il existe de nombreuses difficultés, dont la robustesse des systèmes devant les exemples adverses. Ces derniers sont des points de données assez proches des échantillons valides, mais conçus malicieusement de façon à injecter une perturbation minimale et à forcer le réseau à prendre une mauvaise décision.
Les exemples adverses sont plus que de simples points aléatoires et aveugles dans l’ensemble des données d’entrée, pouvant faire échouer un réseau neuronal très précis. Ils résultent plutôt de l’exploitation consciente des faiblesses du système. Ces faiblesses peuvent être causées, par exemple, par les optimisations bon marché utilisées pour entraîner les réseaux afin d’économiser des ressources, ou encore une représentation numérique imprécise lors de l’encodage d’informations dans un environnement 8 bits dans le cas des images. Mais, plus fondamental encore, de nombreuses techniques adverses utilisées lors d’une attaque reposent sur le même concept de suivi du gradient, ou de variations du signal se propageant d’une couche du réseau à l’autre, et dont l’objectif est de trouver la plus petite perturbation possible à intégrer à une donnée candidate pour la déformer en un exemple adverse.
L’entraînement adverse, un gain en robustesse
Dans ce travail, nous avons exploré la possibilité de contrer l’effet négatif des exemples adverses et de rendre nos modèles moins sujets aux erreurs en améliorant la robustesse du réseau neuronal résultant. À cette fin, nous avons introduit un entraînement adverse ou, en d’autres termes, incorporé intentionnellement des spectrogrammes audio adverses pendant l’entraînement afin d’aider le réseau à mieux résister lors d’inférences futures.
Avant de passer à la phase adverse de nos essais, nous devions d’abord décider du type de modèle à attaquer, et notre choix s’est arrêté sur six types de réseaux de neurones convolutifs, depuis le classique AlexNet jusqu’à la famille des modèles ResNet. Quant à la représentation des données, nous avons complété nos spectrogrammes de Fourier et d’ondelettes par une fonction de détection des changements harmoniques (HCDF) fournie par chromatogramme utilisant la transformée Constant-Q (CQT).
Après avoir défini les architectures réseau et les caractéristiques d’entrée, l’étape suivante a été de sélectionner des attaques éprouvées, la plupart d’entre elles fonctionnant selon le scénario de type boîte blanche où l’adversaire a accès aux paramètres du réseau neuronal de la victime. Et pour augmenter la difficulté, les menaces étaient des attaques ciblées, ce qui signifie que l’adversaire était en mesure d’optimiser son candidat malveillant de façon à pousser le résultat vers une classe erronée précise, et non vers un échec aléatoire. Dans tous les cas, le taux de réussite de tous les algorithmes d’attaque a été fixé à un seuil de réussite prédéfini de 90 %, après avoir réglé avec précision plusieurs hyperparamètres tels que les limites de perturbation, le nombre d’itérations et le nombre de recherches de lignes dans la sélection d’échantillons.
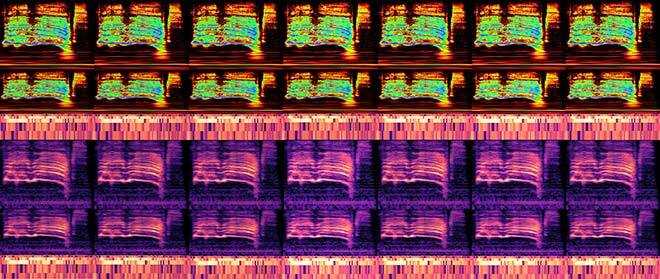
Fig. 1 Spectrogrammes adverses élaborés pour ResNet-56 au moyen de six algorithmes d’attaque optimisés, à différentes valeurs adverses de perturbation ϵ.
Les bases de données d’où les fichiers audio ont été prélevés étaient formées de sons environnementaux (UltraSound8K et ESC-50) comptant respectivement dix et cinquante classes différentes et totalisant des milliers d’exemples. L’entraînement a été effectué principalement sur des GPU NVIDIA à partir des serveurs de l’ÉTS.
Un nouvel entraînement des modèles avec des exemples adverses additionnels nous a permis de constater une baisse de performance dans la précision de la reconnaissance par rapport au modèle original. Par contre, nous avons remarqué un gain important de robustesse contre les exemples adverses fabriqués, mais dans tous les cas, l’entraînement adverse n’a pas pu empêcher complètement le réseau de mal classer les exemples adverses.
Conclusion
La principale contribution de notre recherche est, en plus de l’amélioration de la robustesse des modèles, l’augmentation considérable du coût des perturbations à introduire dans l’échantillon malveillant lors d’attaques, ce qui les rend difficiles à réaliser dans une configuration réelle sans être remarquées. Il reste encore beaucoup à faire pour proposer une défense efficace contre les exemples adverses; l’entraînement des modèles au moyen d’exemples adverses demeure un compromis entre performance de classification et robustesse du système et ne constitue pas une solution pour éliminer ces menaces.
Informations supplémentaires
Pour plus d’informations sur cette recherche, consulter les articles suivants : Raymel, A.S.; Esmaeilpour, M.; Cardinal, P. 2020. “Adversarially Training for Audio Classifiers.” Présenté à l’International Conference on Pattern Recognition.


