
Une approche simplifiée pour reconnaître les émotions dans les vidéos

Achetée sur Istock.com.
La reconnaissance des émotions dans des images vidéo est difficile, car elle nécessite de distinguer les légères déformations du visage humain représentant des émotions, tout en ne tenant pas compte de différences visuelles plus importantes, résultant des traits du visage uniques à chaque personne. Ces dernières années, la technique d’extraction des caractéristiques du visage par réseaux neuronaux profonds a apporté d’énormes progrès en reconnaissance d’émotions. Dans ce travail, nous proposons une approche plus simple qui combine les réseaux neuronaux convolutifs (Convolutional Neural Networks, CNN) [1] entraînés sur un ensemble de données publiques d’images faciales à (1) un mécanisme d’attention spatiale localisant les régions les plus importantes du visage, qui montrent une émotion donnée, et (2) à un mécanisme de regroupement temporel sélectionnant les images les plus importantes d’une vidéo donnée. Mots-clés : Informatique affective, reconnaissance des émotions, mécanismes d’attention, réseaux neuronaux convolutifs.
La reconnaissance des émotions, un défi
Les êtres humains communiquent entre eux par voie de canaux implicites comme les émotions. Pour réussir une interaction humain-machine, un système informatique doit comprendre les émotions et y répondre adéquatement. De nos jours, les progrès de la technologie facilitent de plus en plus l’interprétation des canaux explicites. Par exemple, les systèmes de traitement vocal convertissent aisément une voix en texte, et les systèmes de vision par ordinateur peuvent détecter un visage dans une image. Récemment, la reconnaissance des émotions attire l’attention non seulement des acteurs en vision par ordinateur, mais de ceux du traitement du langage naturel et de la parole, car les méthodes actuelles donnent enfin des résultats comparables aux performances humaines.
Concevoir un système capable d’encoder les caractéristiques discriminantes pour la reconnaissance d’émotions dans les images vidéo représente un défi, car les visages peuvent varier beaucoup en fonction du sujet, des conditions de capture (pose, éclairage, flou) et des détecteurs. Il est difficile de coder les caractéristiques spatio-temporels communes et discriminants des émotions tout en supprimant le contexte et les variations faciales spécifiques au sujet.
Pour aborder la reconnaissance des émotions au sens large, notre processus comprenait quatre étapes : le prétraitement, l’extraction des traits, le regroupement spatial et le regroupement temporel.
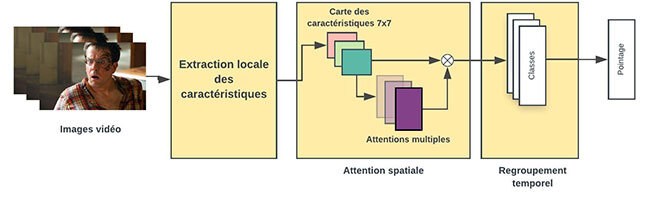
Figure 1 Aperçu de la méthodologie
Prétraitement
Considérant la vidéo d’un point de vue visuel, les expressions faciales transmettent généralement la plupart des informations émotionnelles. Cependant, chaque image d’une vidéo montre, en plus du visage humain, de nombreux objets non reliés. La première tâche consiste donc à extraire le visage de chaque image vidéo.
Extraction des caractéristiques
Dans cette étape, les visages extraits de chaque image sont entrés dans des réseaux neuronaux convolutifs (CNN) entraînés. Le CNN est une sorte de modèle qui prend une image d’entrée et la fait passer par une série de filtres d’apprentissage (noyaux), attribuant un degré d’importance aux divers aspects ou objets de l’image. À la fin de cette étape, on obtient les caractéristiques du visage correspondant à une émotion dans chaque image de la vidéo.
Regroupement spatial
Le CNN traite chaque couche du modèle dans l’image en diminuant la résolution d’entrée et en augmentant la résolution de sortie (caractéristiques). Lors de la reconnaissance des émotions, plusieurs parties du visage contribuent à son expression, et de nombreuses parties ont une influence simultanée sur le résultat. Par conséquent, notre hypothèse est qu’en visant explicitement les régions importantes du visage, le modèle peut mieux tirer profit des caractéristiques du CNN. C’est pourquoi nous avons utilisé le réseau d’attention à ce stade. Les modèles d’attention [2] augmentent l’interprétabilité des représentations internes du réseau neuronal profond en capturant la zone sur laquelle le modèle concentre son attention lors de l’exécution d’une tâche.
Regroupement temporel
Dans les étapes précédentes, l’attention est portée sur une image à la fois dans une vidéo; toutefois, c’est l’ensemble des images d’une vidéo qui contribuent à l’émotion finale. Par conséquent, nous devons considérer les expressions faciales dans le temps pour mieux comprendre l’émotion associée à la vidéo. Les approches les plus courantes, soit la valeur la plus élevée (regroupement maximal) ou moyenne (regroupement moyen) dans la vidéo, ignorent totalement ou lissent trop la relation entre chaque image dans une vidéo. Afin de régler le problème, nous avons eu recours à une nouvelle méthode d’agrégation qui agit comme un entre-deux. Nous comparons également notre nouvelle approche de regroupement temporel avec le LSTM (long short-term memory) [4], un réseau neuronal particulier capable de prendre en compte la dimension temporelle.
Évaluation de l’approche proposée

Figure 2 Échantillon de la base de données AFEW
Nous avons évalué nos modèles à l’aide de la base de données AFEW, utilisée dans le sous-défi audio-vidéo EmotiW [3]. La AFEW est composée de films et d’émissions de télé-réalité ; elle contient 773 clips vidéo pour l’apprentissage et 383 pour la validation. Elle met de l’avant 7 émotions différentes : colère, dégoût, peur, bonheur, tristesse, surprise et neutre. La figure 2 illustre des exemples d’images tirées de l’ensemble de données. Le résultat de l’attention spatiale est plus facile à percevoir sous forme visuelle. Dans la figure 3, chaque image prise sur le terrain dans une séquence a sa carte thermique correspondante, montrant les régions du visage concernées, et un tableau sur l’intensité des émotions associées à cette image précise. La deuxième carte thermique montre clairement que le modèle ne se limite pas dans toutes les images à capturer la bouche, partie la plus importante pour détecter l’émotion dans ce cas-ci, mais inclut aussi les yeux dans les trois dernières images.
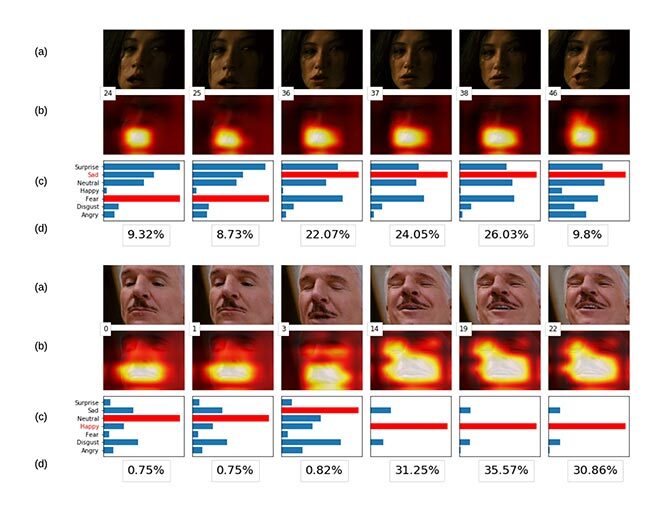
Figure 3 Images vidéo séquentielles d’un exemple de tristesse et de bonheur. Le pourcentage sous les graphiques représente l’importance temporelle des images sélectionnées. Les valeurs ont été renormalisées entre 0 et 100 % pour les rendre plus probantes.
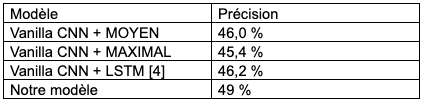
Dans le tableau 1, nous présentons les performances de notre modèle. Par rapport aux modèles de base, notre méthode permet d’obtenir une plus grande précision.
Tableau 1 : Nous avons évalué la performance de l’attention spatiale et du regroupement temporel proposés,
et l’avons comparée à un modèle de référence qui n’en avait pas.
Conclusion
Notre travail consistait à présenter deux stratégies simples pour améliorer la reconnaissance des émotions dans les séquences vidéo. D’abord, nous avons eu recours à un mécanisme d’attention pour la sélection spatiale des régions les plus importantes d’une image. Ensuite, nous avons démontré qu’en considérant la relation entre chaque image d’une vidéo, non seulement le modèle sélectionne les images les plus importantes, mais il tend également à donner des résultats prometteurs.
Information supplémentaire
Pour plus d’informations sur cette recherche, lire l’article suivant, ayant remporté le prix du meilleur article : Aminbeidokhti, M. ; Pedersoli, M. ; Cardinal, P. Granger, E. 2019. “Emotion Recognition with Spatial Attention and Temporal Softmax Pooling”. In: Karray F., Campilho A., Yu A. (eds) Image Analysis and Recognition. ICIAR 2019. Lecture Notes in Computer Science, vol 11662. Springer, Cham.


